How I update and fix broken and invalid ebooks… automatically
For the past few months, I have been experimenting with ebook import for Bookalope. At first, it was just a fun idea, but the more I’ve thought about it, the more it makes sense.
What if, for example, I could take an outdated, invalid, or even broken ebook, feed it into Bookalope, and automatically get an updated, valid, and fixed ebook for my effort? And because Bookalope is all about intelligent automation, could I update and fix a whole batch of ebooks in one go? What about ebook accessibility? Could I add or improve that as well?
Along with Kindle’s somewhat proprietary MOBI format, the open EPUB standard format has been around for a while, and it’s the defining format for most of today’s ebooks. Over the years, the format’s evolution has resulted in a large number of now outdated ebooks. Perhaps unsurprisingly, the majority of these are also either invalid or broken.
So, while I’ve been looking at ebook import for Bookalope as an interesting engineering challenge, it certainly makes a lot of sense for a significant number of publishers out there to update (and possibly fix) their existing ebook libraries, too.
But let’s start simple.
What is an outdated, invalid, or broken ebook anyway?
The current (just released) EPUB standard version is 3.2, which, after many years, has finally superseded the venerable version 3.0.1. However, out in the real world, there remains a plethora of ebooks in EPUB 2.1 format, which doesn’t support HTML5, CSS3, or several other features of modern ebook reading devices.
The EPUB standard also prescribes a certain internal structure for an ebook, and if these rules aren’t met, then the ebook is considered invalid. For me personally, an invalid ebook is already broken, but it might still render OK on my reader. (This means that the ebook may look superficially fine even if it contains deeper internal problems.) And finally, there are those ebooks that don’t even render properly.
There are two tools that I use regularly to check if an ebook is valid: Flightdeck, a comprehensive test suite, and EpubCheck. As a requirement, every ebook that Bookalope produces must run through both without making a peep, otherwise there’s a bug in Bookalope’s code that needs fixing.
Let’s take a look at a random ebook that a customer gave me to test:
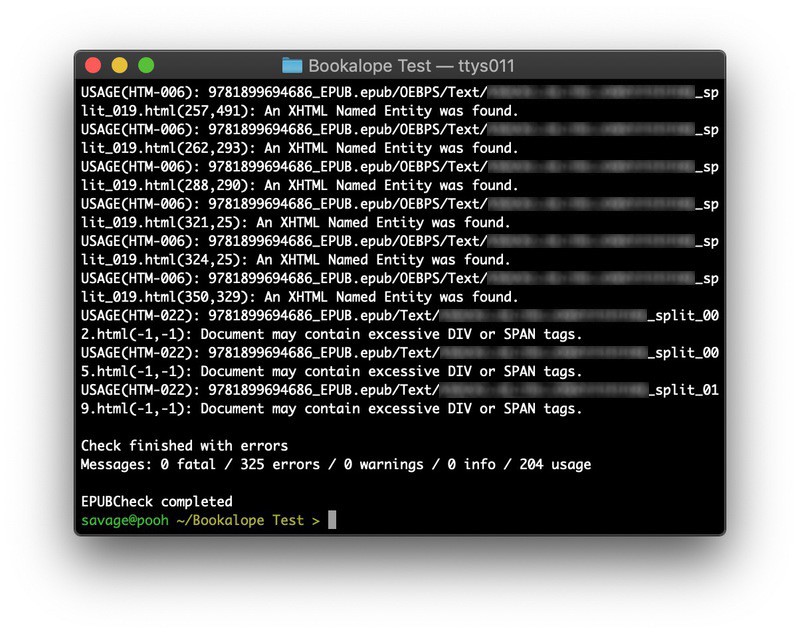
Many of the errors repeat across the chapters in this ebook (and do so in many ebooks, for that matter). The most common issues I see with invalid or broken ebooks are invalid X/HTML documents (e.g. missing or colliding element attributes), incorrect element sequences and nesting, problems with CSS classes and syntax, and general bugs in the EPUB’s scaffolding files. One of the oddest issues I’ve seen, however, was an old ebook that was built on Windows whose internal ZIP index still contained MS-DOS style backslash paths!
Let’s fix this ebook
There are different ways of using Bookalope for an invalid ebook, but for this particular write-up, I wanted true automation. And true automation means shell scripting. So, I wrote myself a helper script called epubdate.sh that talks directly to the Bookalope server. You can download that script here.
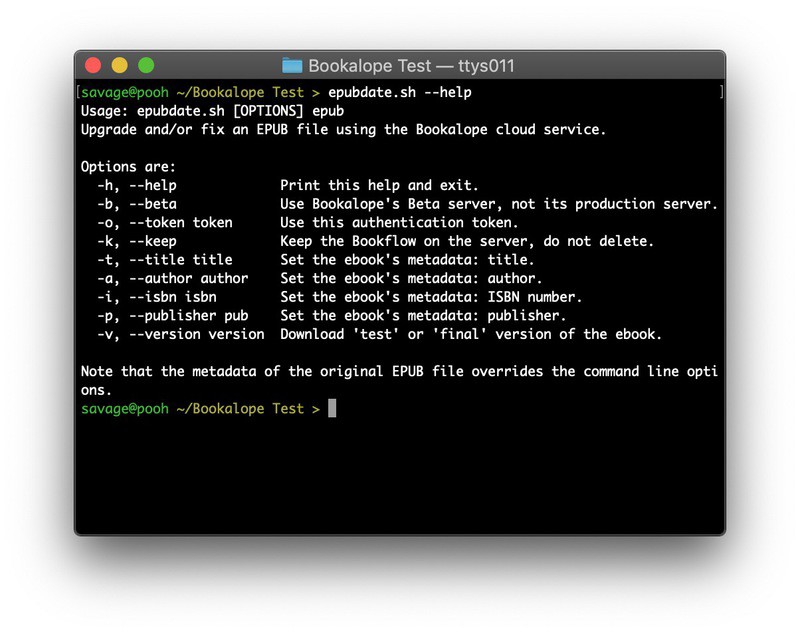
epubdate.sh script talks directly to the Bookalope server which updates and fixes the EPUB file.The command-line arguments are probably quite self-explanatory. Two of them, though, are required by the script to work, and the rest are optional. The first required argument is my authorization token, which comes with my Bookalope account, and the second one is the EPUB file itself.
When run, the script uploads the ebook to the Bookalope server, and then waits for the server to respond with the converted and fixed EPUB file. Here’s what that looks like:
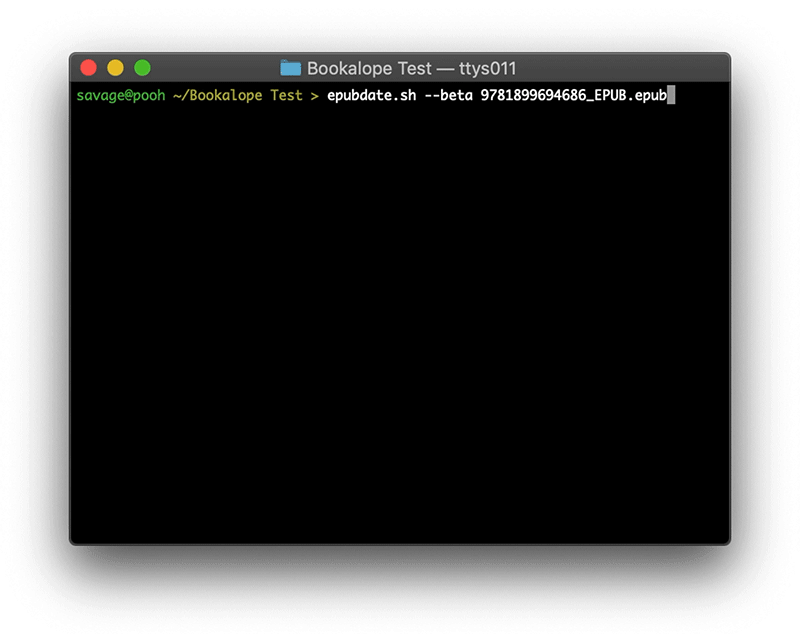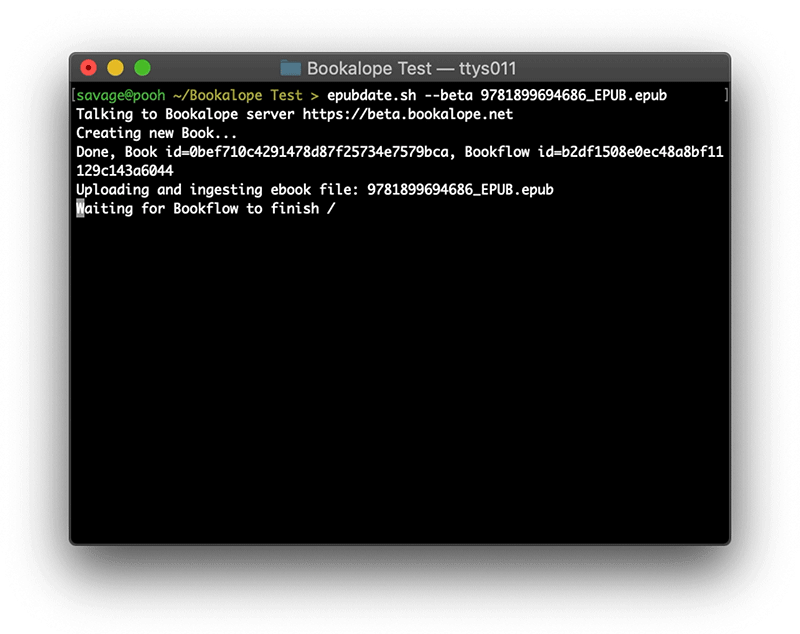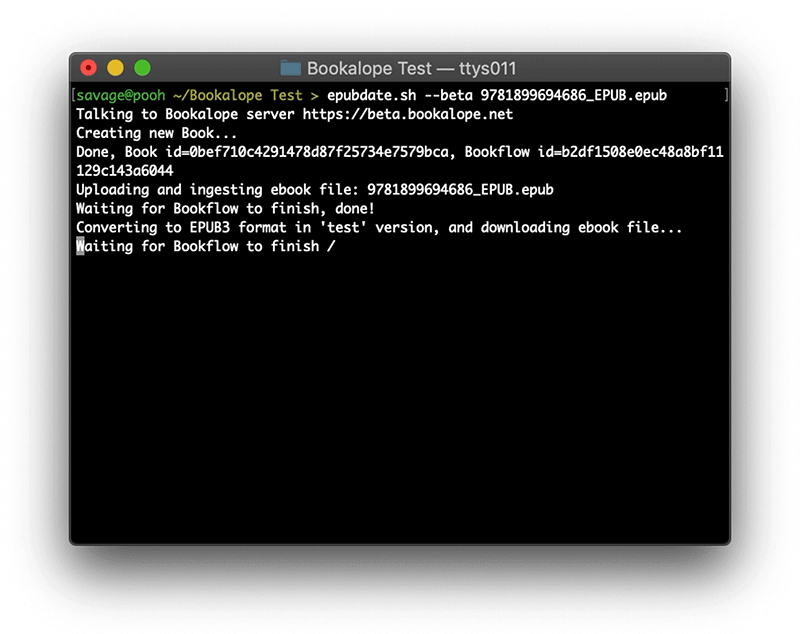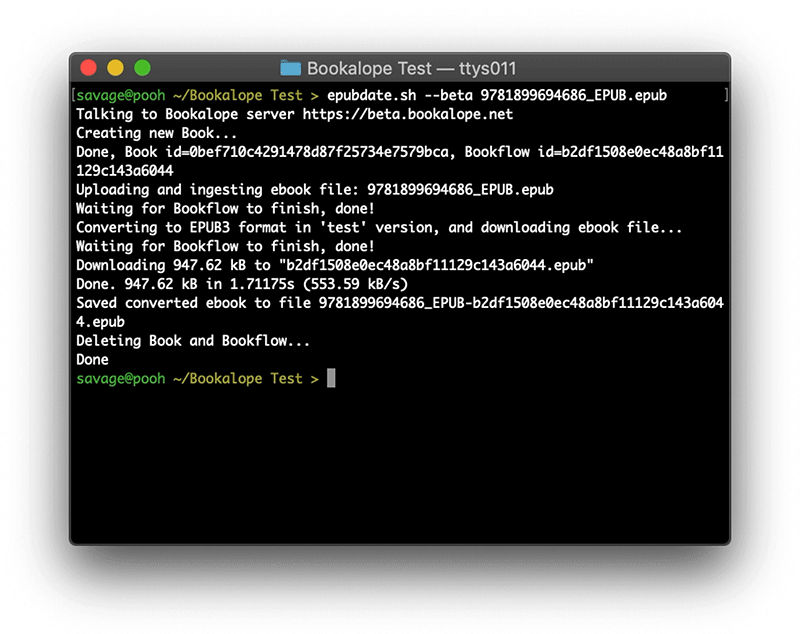
epubdate.sh script to update and fix the example ebook.The heavy lifting is done by the Bookalope tools on the server. First, the uploaded ebook is disassembled and its internal files are consolidated in their respective reading order, including most of their visual styling. Because the script explicitly disables Bookalope’s AI-assisted structure analysis (a topic for another blog post), it requests only minimal accessibility support for this ebook. So, the server skips all of the semantic structure analysis and simply takes the consolidated content, cleans it up, and reassembles everything from scratch into a new and valid EPUB file of the latest version. Lastly, the server signals that the work is done and the script downloads the new ebook.
Bookalope’s ebook import is still experimental and remains a work in progress. At the moment it can cause ebooks with complex nested elements and elaborate design (e.g. academic ebooks) to lose some visual features—so be careful.
The epubdate.sh script demonstrates how automation and intelligent tools help us improve our daily work. Note, however, that this script is just one example of integrating the Bookalope cloud service into a custom environment, in this case a simple shell script. Another example would be Bookalope’s extension for InDesign. It is easy to integrate the Bookalope tools into your own workflow by using existing language interfaces for Python, Javascript, or PHP, all of which are available on GitHub.
So, that’s how I update and fix ebooks; well, Bookalope does the work, and I can slurp a hot chocolate.
How do you noodle through dozens of outdated and broken ebooks?